library(tidyverse)
library(easystats)
library(tidymodels)
library(tidytext) # Textmiing
library(textrecipes) # Textanalysen in Tidymodels-Rezepten
library(lsa) # stopwords
library(discrim) # naive bayes classification
library(naivebayes)
library(tictoc) # Zeitmessung
library(fastrtext) # Worteinbettungen
library(remoji) # Emojis
library(tokenizers) # Vektoren tokenisieren
library(tictoc) # Zeitmessung
source("funs/helper-funs-recipes.R")10 Klassifikation von Hatespeech
10.1 Vorab
10.1.1 Lernziele
- Sie können grundlegende Verfahren zur Klassifikation von Hatespeech einsetzen und erklären
10.1.2 Benötigte R-Pakete und Skripte
10.2 Daten
Für Maschinenlernen brauchen wir Trainingsdaten, Daten also, bei denen wir pro Beobachtung der Wert der Zielvariablen kennen. Man spricht auch von “gelabelten” Daten.
Wir nutzen die Daten von Wiegand (2019a) bzw. Wiegand (2019b). Die Daten sind unter CC-By-4.0 Int. lizensiert.
d_raw <-
data_read("data/germeval2018.training.txt",
header = FALSE,
quote = "")Die Daten finden sich auch im Paket pradadata.
Da die Daten keine Spaltenköpfe haben, informieren wir die Funktion dazu mit header = FALSE.
Benennen wir die die Spalten um:
Dabei soll c1 und c2 für die 1. bzw. 2. Klassifikation stehen.
In c1 finden sich diese Werte:
Mit c1 wurde klassifiziert, ob beleidigende Sprache (offensive language) vorlag oder nicht (Risch u. a. 2021, 2), also OFFENSE bzw. OTHER:
Task 1 was to decide whether a tweet includes some form of offensive language or not. The tweets had to be classified into the two classes OFFENSE and OTHER. The OFFENSE category covered abusive language, insults, as well as merely profane statements.
Und in c2 finden sich die vier Ausprägungen ABUSE, INSULT, PROFANITY und OTHER:
In c2 ging es um eine feinere Klassifikation beleidigender Sprache (Risch u. a. 2021, 2):
The second task involved four categories, a nonoffensive OTHER class and three sub-categories of what is OFFENSE in Task 1. In the case of PROFANITY, profane words are used, however, the tweet does not want to insult anyone. This typically concerns the usage of swearwords (Scheiße, Fuck etc.) and cursing (Zur Hölle! Verdammt! etc.). This can be often found in youth language. Swearwords and cursing may, but need not, co-occur with insults or abusive speech. Profane language may in fact be used in tweets with positive sentiment to express emphasis. Whenever profane words are not directed towards a specific person or group of persons and there are no separate cues of INSULT or ABUSE, then tweets are labeled as simple cases of PROFANITY.
Sind Texte, die als OFFENSE klassifiziert sind, auch (fast) immer nie als OTHER, sondern stattdessen als ABUSE, INSULT oder PROFANITY klassifiziert?
In ca. 2/3 der Fälle wurden in beiden Klassifikation OTHER klassifiziert:
Entsprechend in ca. 1/3 der Fälle wurde jeweils nicht mit OTHER klassifiziert.
Wir begnügen uns hier mit der ersten, gröberen Klassifikation.
Fügen wir abschließend noch eine ID-Variable hinzu:
d1 <-
d_raw %>%
mutate(id = as.character(1:nrow(.)))Die ID-Variable definieren als Text (nicht als Integer), da die Twitter-IDs zwar natürliche Zahlen sind, aber zu groß, um von R als Integer verarbeitet zu werden. Faktisch sind sie für uns auch nur nominal skalierte Variablen, so dass wir keinen Informationsverlust haben.
#write_rds(d1, "objects/d1.rds")10.3 Feature Engineering
Reichern wir die Daten mit weiteren Features an, in der Hoffnung, damit eine bessere Klassifikation erzielen zu können.
10.3.1 Textlänge
d2 <-
d1 %>%
mutate(text_length = str_length(text))
head(d2)10.3.2 Sentimentanalyse
Wir nutzen dazu SentiWS (Remus, Quasthoff, und Heyer 2010).
sentiws <- read_csv("https://osf.io/x89wq/?action=download")
## Rows: 3468 Columns: 4
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (3): neg_pos, word, inflections
## dbl (1): value
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.d2_long <-
d2 %>%
unnest_tokens(input = text, output = token)
head(d2_long)Jetzt filtern wir unsere Textdaten so, dass nur Wörter mit Sentimentwert übrig bleiben:
d2_long_senti <-
d2_long %>%
inner_join(sentiws %>% select(-inflections), by = c("token" = "word"))
## Warning in inner_join(., sentiws %>% select(-inflections), by = c(token = "word")): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 1559 of `x` matches multiple rows in `y`.
## ℹ Row 2572 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.
head(d2_long)Schließlich berechnen wir die Sentimentwert pro Polarität und pro Tweet:
d2_sentis <-
d2_long_senti %>%
group_by(id, neg_pos) %>%
summarise(senti_avg = mean(value))
## `summarise()` has grouped output by 'id'. You can override using the `.groups`
## argument.
head(d2_sentis)Diese Tabelle bringen wir wieder eine breitere Form, um sie dann wieder mit den Hauptdaten zu vereinigen.
d2_sentis_wide <-
d2_sentis %>%
pivot_wider(names_from = "neg_pos", values_from = "senti_avg")
d2_sentis_wide %>% head()
Hinweis
Die Sentimentanalyse hier vernachlässigt Flexionen der Wörter. Der Autor fühlt den Drang zu schreiben: “Left as an exercise for the reader” :-)
10.3.3 Schimpfwörter
Zählen wir die Schimpfwörter pro Text. Dazu nutzen wir die Daten von LDNOOBW, lizensiert nach CC-BY-4.0-Int.
schimpf1 <- read_csv("https://raw.githubusercontent.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words/master/de", col_names = FALSE)
## Rows: 66 Columns: 1
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): X1
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Länger aber noch ist die Liste aus dem InsultWiki, lizensiert CC0.
schimpf2 <-
data_read("data/insult-de.txt", header = FALSE) %>%
mutate_all(str_to_lower)Die Daten finden sich auch im Paket pradadata.
Binden wir die Listen zusammen:
Um die Lesis vor (unnötiger?) Kopfverschmutzung zu bewahren, sind diese Schimpfwörter hier nicht abgedruckt.
Jetzt zählen wir, ob unsere Tweets/Texte solcherlei Wörter enthalten.
Wie viele Schimpfwörter haben wir gefunden?
Etwa ein Prozent der Wörter (ca. 1k) sind Schimpfwörter in unserem Corpus.
Wichtig
Namen wie final, main oder result sind gefährlich, da es unter Garantie ein “final-final geben wird, oder der”Haupt-Datensatz” plötzlich nicht mehr so wichtig erscheint und so weiter.
10.3.4 Emojis
emj <- emoji(list_emoji(), pad = FALSE)
head(emj)
## [1] "😄" "😃" "😀" "😊" "☺️" "😉"Diese Liste umfasst knapp 900 Emojis, das sind allerdings noch nicht alle, die es gibt. Diese Liste umfasst mit gut 1800 Emojis gut das Doppelte.
Selbstkuratierte Liste an “wilden” Emoji; diese Liste ist inspiriert von emojicombos.com.
wild_emojis <-
c(
emoji(find_emoji("gun")),
emoji(find_emoji("bomb")),
emoji(find_emoji("fist")),
emoji(find_emoji("knife"))[1],
emoji(find_emoji("ambulance")),
emoji(find_emoji("fist")),
emoji(find_emoji("skull")),
"☠️", "🗑", "😠", "👹", "💩" ,
"🖕", "👎️",
emoji(find_emoji("middle finger")), "😡", "🤢", "🤮",
"😖", "😣", "😩", "😨", "😝", "😳", "😬", "😱", "😵",
"😤", "🤦♀️", "🤦"
)wild_emojis_df <-
tibble(emoji = wild_emojis)
#save(wild_emojis_df, file = "data/wild_emojis.RData")Auf dieser Basis können wir einen Prädiktor erstellen, der zählt, ob ein Tweet einen oder mehrere der “wilden” Emojis enthält.
10.4 Workflow 1: TF-IDF + Naive-Bayes
10.4.1 Dummy-Rezept
Hier ist ein einfaches Beispiel, um die Textvorbereitung mit textrecipes zu verdeutlichen.
Wir erstellen uns einen Dummy-Text:
Dann tokenisieren wir den Text:
rec_dummy <-
recipe(text ~ 1, data = dummy) %>%
step_tokenize(text)
rec_dummy
##
## ── Recipe ──────────────────────────────────────────────────────────────────────
##
## ── Inputs
## Number of variables by role
## outcome: 1
##
## ── Operations
## • Tokenization for: textDie Tokens kann man sich so zeigen lassen:
show_tokens(rec_dummy, text)
## [[1]]
## [1] "ich" "gehe" "heim" "und" "der" "die" "das" "nicht" "in"
## [10] "ein" "and" "the"Jetzt entfernen wir die Stopwörter deutscher Sprache; dafür nutzen wir die Stopwort-Quelle snowball:
rec_dummy <-
recipe(text ~ 1, data = dummy) %>%
step_tokenize(text) %>%
step_stopwords(text, language = "de", stopword_source = "snowball")
rec_dummy
##
## ── Recipe ──────────────────────────────────────────────────────────────────────
##
## ── Inputs
## Number of variables by role
## outcome: 1
##
## ── Operations
## • Tokenization for: text
## • Stop word removal for: textPrüfen wir die Tokens; sind die Stopwörter wirklich entfernt?
show_tokens(rec_dummy, text)
## [[1]]
## [1] "gehe" "heim" "and" "the"Ja, die deutschen Stopwörter sind entfernt. Die englischen nicht; das macht Sinn!
10.4.2 Datenaufteilung
Den Datensatz d_main kann man sich auch hier importieren:
#d_main <- read_rds(file = "objects/chap-klassifik/d_main.rds")d_split <- initial_split(d_main, strata = c1)
d_train <- training(d_split)
d_test <- testing(d_split)10.4.3 Rezept
Rezept definieren:
rec1 <-
recipe(c1 ~ ., data = select(d_train, text, c1, id)) %>%
update_role(id, new_role = "id") %>%
# step_mutate(text_copy = text) |>
step_tokenize(text) %>%
step_stopwords(text, language = "de", stopword_source = "snowball") %>%
step_stem(text) %>%
step_tokenfilter(text, max_tokens = 1e2) %>% # wir behalten nur die häufigsten Tokens
step_tfidf(text)
rec1
##
## ── Recipe ──────────────────────────────────────────────────────────────────────
##
## ── Inputs
## Number of variables by role
## outcome: 1
## predictor: 1
## id: 1
##
## ── Operations
## • Tokenization for: text
## • Stop word removal for: text
## • Stemming for: text
## • Text filtering for: text
## • Term frequency-inverse document frequency with: textPreppen. Und backen:
10.4.4 Modellspezifikation
Wir definiere einen Naive-Bayes-Algorithmus:
nb_spec <- naive_Bayes() %>%
set_mode("classification") %>%
set_engine("naivebayes")
nb_spec
## Naive Bayes Model Specification (classification)
##
## Computational engine: naivebayesUnd setzen auf die 5-fache Kreuzvalidierung.
set.seed(42)
folds1 <- vfold_cv(d_train, v = 5)10.4.5 Workflow
wf1 <-
workflow() %>%
add_recipe(rec1) %>%
add_model(nb_spec)
wf1
## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: naive_Bayes()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 5 Recipe Steps
##
## • step_tokenize()
## • step_stopwords()
## • step_stem()
## • step_tokenfilter()
## • step_tfidf()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Naive Bayes Model Specification (classification)
##
## Computational engine: naivebayes10.4.6 Fitting
fit1 <-
fit_resamples(
wf1,
folds1,
control = control_resamples(save_pred = TRUE)
)Die Vorhersagen speichern wir ab, um die Performanz in den Faltungen des Hold-out-Samples zu berechnen.
Möchte man sich die Zeit sparen, die Syntax wieder durchlaufen zu lassen, kann man das Objekt speichern. Aber Vorsicht: Dabei kann es passieren, dass man mit veralteten Objekten arbeitet.
#write_rds(fit1, "objects/chap-klassifik/chap_classific_fit1.rds")10.4.7 Performanz
wf1_performance <-
collect_metrics(fit1)
wf1_performance

10.5 Nullmodell
null_classification <-
parsnip::null_model() %>%
set_engine("parsnip") %>%
set_mode("classification")
null_rs <- workflow() %>%
add_recipe(rec1) %>%
add_model(null_classification) %>%
fit_resamples(
folds1
)Hier ist die Performanz des Nullmodells.
null_rs %>%
collect_metrics()show_best(null_rs)
## Warning: No value of `metric` was given; metric 'roc_auc' will be used.10.6 Workflow 2a: Textfeatures + Naive-Bayes
10.6.1 Rezept
Testen wir die Funktionen, die wir im Folgenden nutzen, um Text-Features zu erzeugen:
Rezept definieren:
rec2a <-
recipe(c1 ~ ., data = select(d_train, text, c1, id)) %>%
update_role(id, new_role = "id") %>%
step_text_normalization(text) %>% # UTF8-Normalisiuerung
step_mutate(text_copy = text,
profane_n = map_int(text, count_profane),
emo_words_n = map_int(text, count_emo_words),
emojis_n = map_int(text, count_emojis),
wild_emojis_n = map_int(text, count_wild_emojis)
) %>%
step_textfeature(text_copy) %>%
step_tokenize(text, token = "words") %>%
#step_stem(text) %>%
step_tokenfilter(text, max_tokens = 1e2) %>% # wir behalten nur die häufigsten Tokens
step_stopwords(text, language = "de", stopword_source = "snowball") |>
step_tfidf(text)
rec2a
##
## ── Recipe ──────────────────────────────────────────────────────────────────────
##
## ── Inputs
## Number of variables by role
## outcome: 1
## predictor: 1
## id: 1
##
## ── Operations
## • Text Normalization for: text
## • Variable mutation for: text, map_int(text, count_profane), ...
## • Text feature extraction for: text_copy
## • Tokenization for: text
## • Text filtering for: text
## • Stop word removal for: text
## • Term frequency-inverse document frequency with: textEinige Hinweise zum Rezept:
- Das Tokenisieren kommt erst nach den Textfeatures.
- Da
textfeaturesdie Spaltetext“aufisst”, legen wir eine Kopie der Spalte an. - Man darf nicht vergessen, jedem Step zu sagen, auf welche Spalten er sich beziehen soll (z.B.
text).
Preppen:
rec2a_prepped <- prep(rec2a)Und backen:
d_rec2a <- bake(rec2a_prepped, new_data = NULL)Oder importieren aus der Konserve:
10.6.2 Workflow
wf2a <-
workflow() %>%
add_recipe(rec2a) %>%
add_model(nb_spec)
wf2a
## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: naive_Bayes()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 7 Recipe Steps
##
## • step_text_normalization()
## • step_mutate()
## • step_textfeature()
## • step_tokenize()
## • step_tokenfilter()
## • step_stopwords()
## • step_tfidf()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Naive Bayes Model Specification (classification)
##
## Computational engine: naivebayes10.6.3 Fitting
fit2a <-
fit_resamples(
wf2a,
resamples = vfold_cv(d_train, v = 5),
control = control_resamples(save_pred = TRUE)
)Die Vorhersagen speichern wir ab, um die Performanz in den Faltungen des Hold-out-Samples zu berechnen.
Möchte man sich die Zeit sparen, die Syntax wieder durchlaufen zu lassen, kann man das Objekt speichern. Aber Vorsicht: Dabei kann es passieren, dass man mit veralteten Objekten arbeitet. \(\square\)
#write_rds(fit2a, "objects/chap-klassifik/chap_classific_fit2a.rds")10.6.4 Performanz
wf2a_performance <-
collect_metrics(fit2a)
wf2a_performance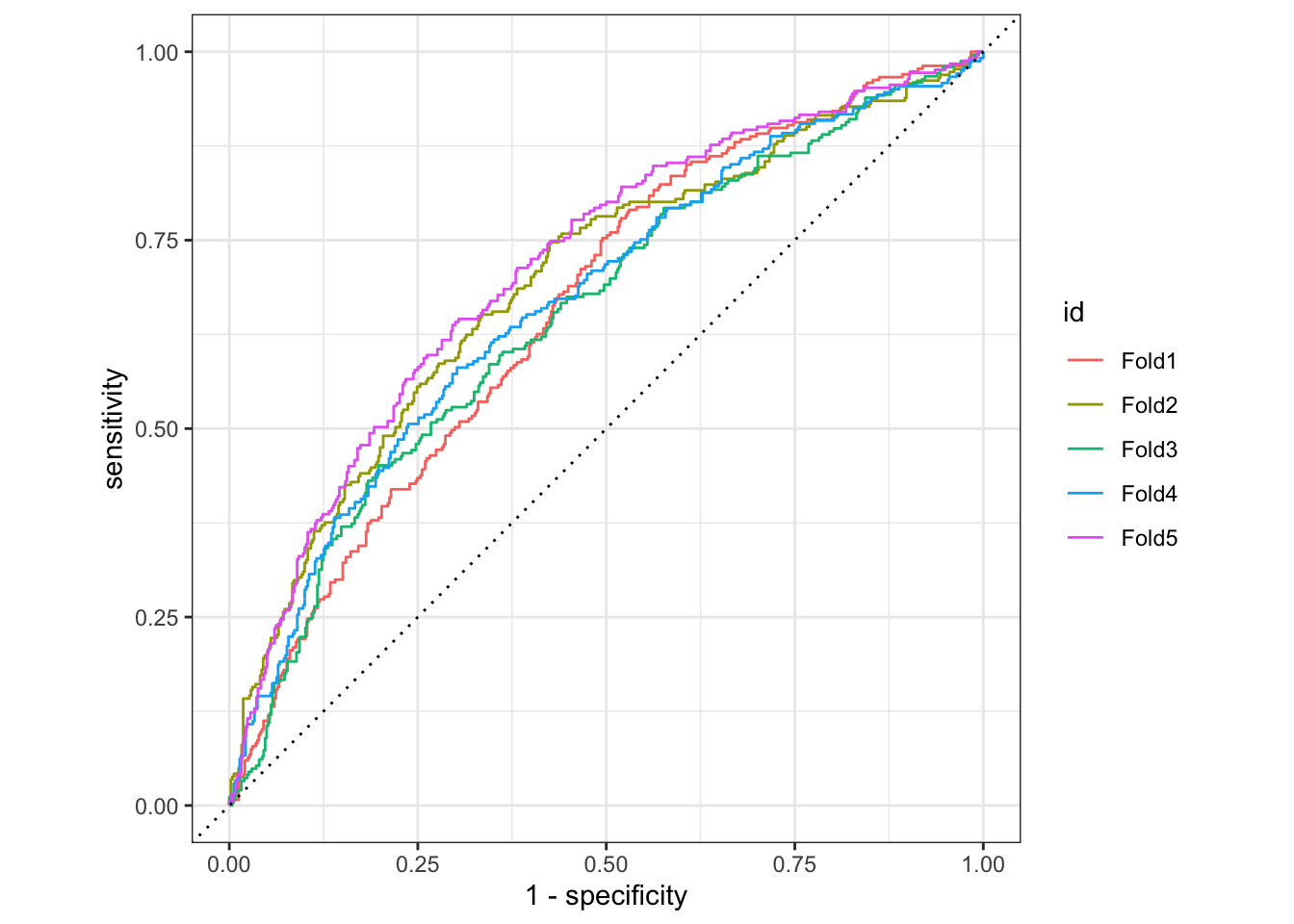
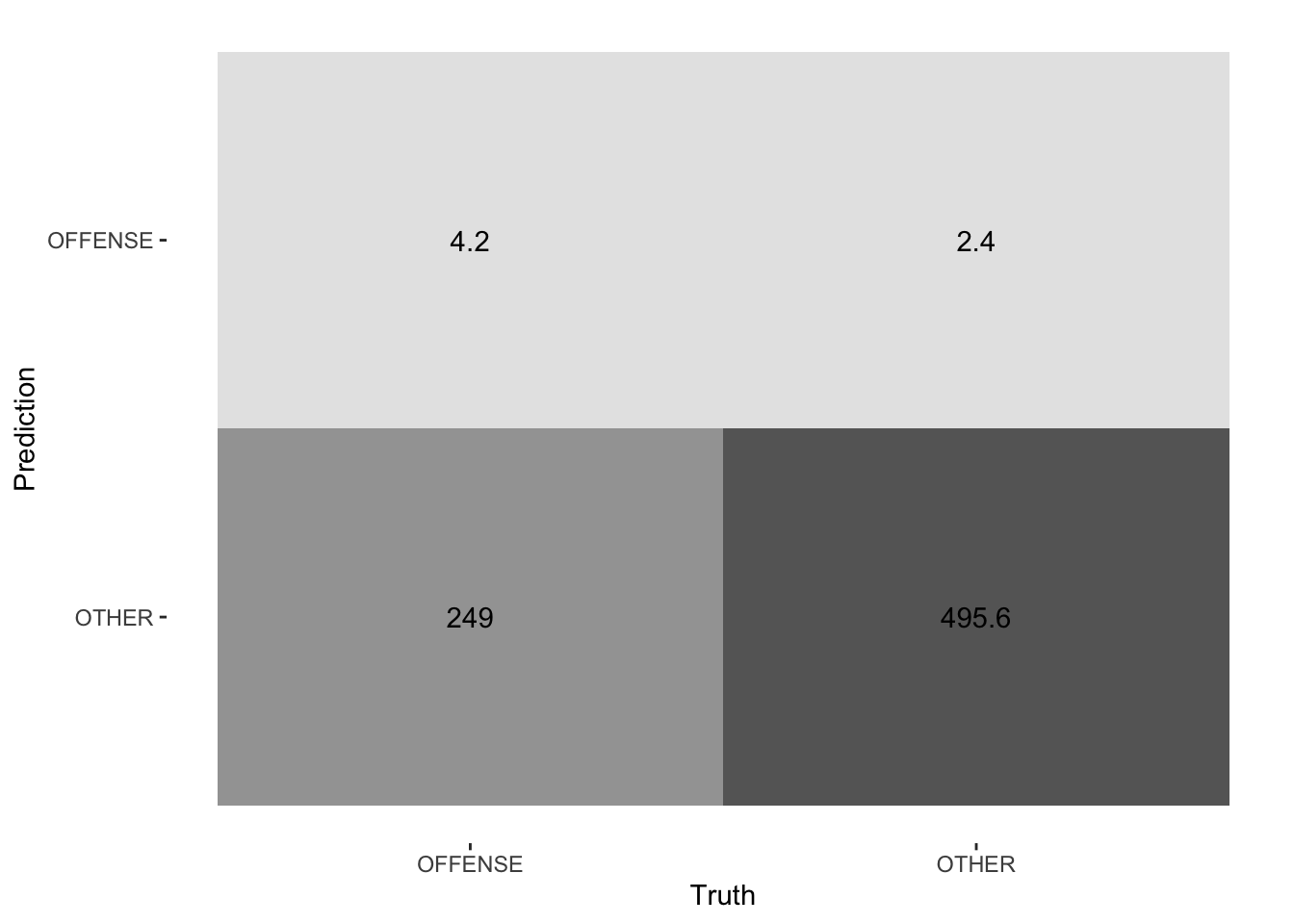
10.7 Workflow 2b: Textfeatures + Lasso
10.7.1 Modell: Lasso
lasso_spec <- logistic_reg(penalty = tune(), mixture = 1) %>%
set_mode("classification") %>%
set_engine("glmnet")
lasso_spec
## Logistic Regression Model Specification (classification)
##
## Main Arguments:
## penalty = tune()
## mixture = 1
##
## Computational engine: glmnetWir definieren die Ausprägungen von penalty, die wir ausprobieren wollen:
lambda_grid <- grid_regular(penalty(), levels = 3) # hier nur 3 Werte, um Rechenzeit zu sparen10.7.2 Workflow
wf2b <-
workflow() %>%
add_recipe(rec1) %>%
add_model(lasso_spec)
wf2b
## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: logistic_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 5 Recipe Steps
##
## • step_tokenize()
## • step_stopwords()
## • step_stem()
## • step_tokenfilter()
## • step_tfidf()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Logistic Regression Model Specification (classification)
##
## Main Arguments:
## penalty = tune()
## mixture = 1
##
## Computational engine: glmnetTunen und Fitten:
set.seed(42)
fit2b <-
tune_grid(
wf2b,
folds1,
grid = lambda_grid,
control = control_resamples(save_pred = TRUE)
)
fit2bVorsicht beim Abspeichern von Objekten: Da kann man leicht vergessen, zu updaten. \(\square\)
#write_rds(fit2b, "objects/chap-klassifik/chap_classific_fit2b.rds")Hier ist die Performanz:
autoplot(fit2b)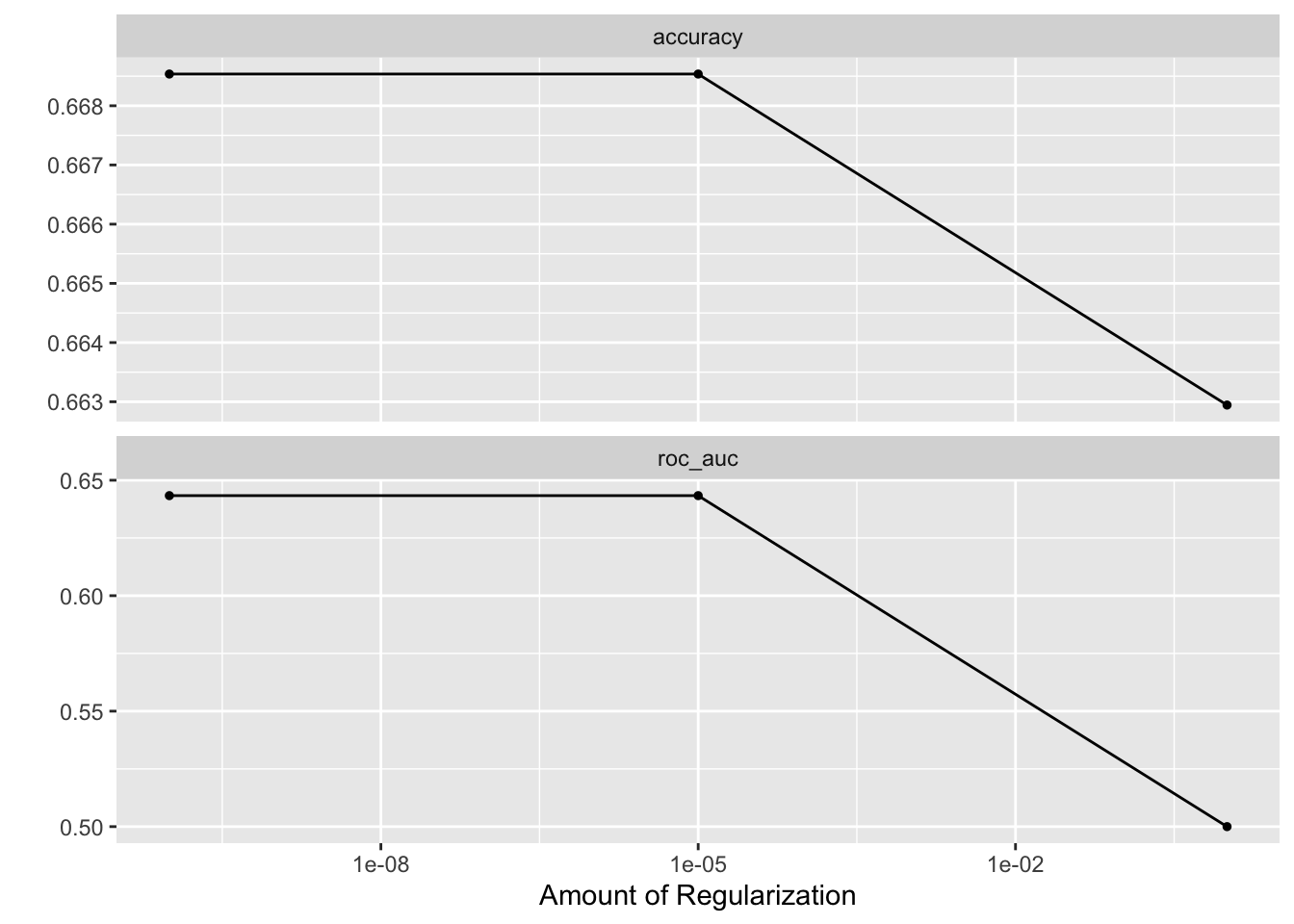
fit2b %>%
show_best("roc_auc")chosen_auc <-
fit2b %>%
select_by_one_std_err(metric = "roc_auc", -penalty)Finalisieren:
wf2b_final <-
finalize_workflow(wf2b, chosen_auc)
wf2b_final
## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: logistic_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 5 Recipe Steps
##
## • step_tokenize()
## • step_stopwords()
## • step_stem()
## • step_tokenfilter()
## • step_tfidf()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Logistic Regression Model Specification (classification)
##
## Main Arguments:
## penalty = 1e-05
## mixture = 1
##
## Computational engine: glmnetfit2b_final_train <-
fit(wf2b_final, d_train)fit2b_final_test <-
last_fit(wf2b_final, d_split)
collect_metrics(fit2b_final_test)10.7.3 Vorhersage
10.7.4 Vohersagedaten
Pfad zu den Daten:
tweet_data_path <- "/Users/sebastiansaueruser/github-repos/hate-speech-data/data-raw/tweets/":::
tweet_data_files_names <- list.files(path = tweet_data_path,
pattern = "tweets-to-.*\\.rds$")
head(tweet_data_files_names)
## [1] "tweets-to-Janine_Wissler_2021.rds" "tweets-to-Janine_Wissler_2022.rds"
## [3] "tweets-to-MAStrackZi_2021.rds" "tweets-to-MAStrackZi_2022.rds"
## [5] "tweets-to-schirdewan_2021.rds" "tweets-to-schirdewan_2022.rds"Wie viele Dateien sind es?
length(tweet_data_files_names)
## [1] 6Wir geben den Elementen des Vektors gängige Namen, das hilft uns gleich bei map:
names(tweet_data_files_names) <-
str_remove(tweet_data_files_names, "\\.rds$") # Datei-Suffix entfernen OK, weiter: So können wir eine der Datendateien einlesen:
Und so lesen wir alle ein:
Zunächst erstellen wir uns eine Helper-Funktion:
Testen:
d1 <- read_and_select(tweet_data_files_names[1])
head(d1)Die Funktion read_and_select mappen wir auf alle Datendateien:
214.531 sec elapsed
Da wir den Elementen von tweet_data_files_names Namen gegeben haben, finden wir diese Namen praktischerweise wieder in ds.
Vielleicht ist es zum Entwickeln besser, mit einem kleineren Datensatz einstweilen zu arbeiten:
ds_short <- read_rds(file = "/Users/sebastiansaueruser/github-repos/hate-speech-data/objects/ds_short.rds") # 300kb
ds <- ds_short10.7.5 Vokabular erstellen
ds_long <-
ds %>%
select(text) %>%
unnest_tokens(input = text, output = word)Puh, das hat gedauert!
Speichern wir uns diese Daten daher auf die Festplatte:
#write_rds(ds_long, file = paste0(tweet_data_path, "ds_long.rds"))Entfernen wir daraus die Duplikate, um uns ein Vokabular zu erstellen:
Insgesamt umfasst nrow(ds_voc) Wörter.
Und das resultierende Objekt speichern wir wieder ab:
#write_rds(ds_voc, file = paste0("objects/", "ds_voc.rds"))10.8 Worteinbettungen erstellen
👨🏫 Hey ChatGPT, beschreibe Das FastText-Modell für Worteinbettungen.
🤖 Ja, Moment…
10.8.1 Was ist das FastText-Modell?
Das FastText-Modell für Worteinbettungen (auch als Word Embeddings bezeichnet) ist ein NLP-Modell, das von Facebook AI Research entwickelt wurde. Es ist eine Erweiterung des klassischen Word2Vec-Modells und zielt darauf ab, Worte in Vektoren umzuwandeln, um semantische Informationen über Wörter zu erfassen. Der Hauptunterschied zwischen FastText und Word2Vec besteht darin, wie sie Worte darstellen.
Hier sind einige wichtige Merkmale und Unterschiede des FastText-Modells:
Subword-Informationen: Während Word2Vec auf ganzen Wörtern basiert, behandelt FastText Wörter als eine Sammlung von Subwörtern (n-Grammen). Diese Subwörter sind buchstäbliche Teile eines Wortes, die für die Analyse verwendet werden. Zum Beispiel, für das Wort “apple” könnte FastText die Subwörter “ap,” “app,” “ppl,” “ple” usw. berücksichtigen. Dies ermöglicht es dem Modell, semantische Informationen auf Buchstabenebene zu erfassen und seltene Wörter oder Wörter, die nicht im Trainingskorpus enthalten sind, besser zu behandeln.
Pre-trained Modelle: Es stehen vorab trainierte FastText-Modelle in vielen Sprachen zur Verfügung. Diese vortrainierten Modelle können in verschiedenen NLP-Anwendungen verwendet werden, ohne von Grund auf neu trainiert werden zu müssen.
Der Trainingsprozess für ein FastText-Modell umfasst das Lernen von Wortdarstellungen anhand großer Textkorpora. Die resultierenden Wortvektoren können verwendet werden, um semantische Beziehungen zwischen Wörtern zu erkunden, Ähnlichkeiten zu berechnen oder als Eingabe für maschinelle Lernmodelle in verschiedenen natürlichsprachlichen Verarbeitungsaufgaben zu dienen. Insgesamt hat FastText aufgrund seiner Fähigkeit zur Berücksichtigung von Subwörtern und seiner Effizienz bei der Verarbeitung großer Vokabulare in der NLP-Gemeinschaft an Popularität gewonnen.1
10.8.2 Ein Fast-Text-Modell trainieren
Definiere die Konstanten für das fastText-Modell:
Wir können uns ein FastText-Modell für Worteinbettungen basierend auf unseren Daten berechnen lassen:
#writeLines(text = texts, con = out_file_txt)
#execute(commands = c("skipgram", "-input", tmp_file_txt, "-output", out_file_model, "-verbose", 1)) # execute berechnet ein FastText-MdlellIm Standard werden 100 Dimensionen berechnet.
Hier ist schon ein vorab gespeichertes Modell, basierend auf den Twitter-Daten:
out_file_txt <- "/Users/sebastiansaueruser/datasets/Twitter/twitter-polit-model.vec"
out_file_model <- "/Users/sebastiansaueruser/datasets/Twitter/twitter-polit-model.bin"
file.exists(out_file_txt)
## [1] TRUE
file.exists(out_file_model)
## [1] TRUERead 22M words
Number of words: 130328
Number of labels: 0
Progress: 100.0% words/sec/thread: 49218 lr: 0.000000 avg.loss: 1.720812 ETA: 0h 0m 0sJetzt laden wir das Modell von der Festplatte:
twitter_fasttext_model <- load_model(out_file_model)
dict <- get_dictionary(twitter_fasttext_model)Das Wörterbuch umfasst 130328 (verschiedene) Wörter.
Schauen wir uns einige Begriffe aus dem Vokabular an:
Hier sind die ersten paar Elemente des Vektors für menschen:
vec1 <- get_word_vectors(twitter_fasttext_model, c("menschen"))
vec1[1:10] [1] 0.14156282 0.44875699 0.23911817 -0.02580349 0.29811972 0.03870077
[7] 0.06518744 0.22527063 0.28198120 0.39931887Erstellen wir uns einen Tibble, der als erste Spalte das Vokabular und in den übrigen 100 Spalten die Dimensionen enthält:
word_embedding_twitter <-
tibble(
word = dict
)words_vecs_twitter <-
get_word_vectors(twitter_fasttext_model)Und als Worteinbettungsdatei abspeichern:
#write_rds(word_embedding_twitter, file = paste0(tweet_data_path, "word_embedding_twitter.rds"))10.8.3 Aufbereiten
Am besten nur die Spalten (unseres Twitter-Datensatzes) behalten, die wir zum Modellieren nutzen:
Wir definieren ein Rezept rec_word_embed (basierend auf rec1):
rec_word_embed <-
recipe(c1 ~ ., data = select(d_train, text, c1, id)) %>%
update_role(id, new_role = "id") %>%
step_tokenize(text) %>%
step_stopwords(text, language = "de", stopword_source = "snowball") %>%
step_stem(text) %>%
step_tokenfilter(text, max_tokens = 1e2) %>% # wir behalten nur die häufigsten Tokens
step_word_embeddings(text, embeddings = word_embedding_twitter)Dann preppen und backen:
rec_word_embed_prepped <-
prep(rec_word_embed)ds_baked_rec1a <- bake(rec_word_embed_prepped, new_data = ds_short2)ds_baked_rec1a %>% `[`(1:10, 1:10)Ist das nicht komfortabel? Das Textrezept übernimmt die Arbeit für uns, mit den richtigen Features zu arbeiten, und die Wort-Einbettungen für die richtigen Wörter bereitzustellen.
Wer dem Frieden nicht traut, dem sei geraten, nachzuprüfen 🤓.
10.9 Workflow 3: Worteinbettungen + Lasso
10.9.1 Daten aufteilen
d_split <- initial_split(d2, strata = c1)
d_train <- training(d_split)
d_test <- testing(d_split)10.9.2 Hilfsfunktionen
source("funs/helper-funs-recipes.R")10.9.3 Rezept mit Worteinbettungen
rec2 <-
recipe(c1 ~ ., data = select(d_train, text, c1, id)) %>%
update_role(id, new_role = "id") %>%
step_text_normalization(text) %>%
step_mutate(text_copy = text,
profane_n = map_int(text, count_profane),
emo_words_n = map_int(text, count_emo_words),
emojis_n = map_int(text, count_emojis),
wild_emojis_n = map_int(text, count_wild_emojis)
) %>%
step_textfeature(text_copy) %>%
step_tokenize(text, token = "words") %>%
step_stopwords(text, language = "de", stopword_source = "snowball") %>%
step_word_embeddings(text, embeddings = word_embedding_twitter)
rec2
##
## ── Recipe ──────────────────────────────────────────────────────────────────────
##
## ── Inputs
## Number of variables by role
## outcome: 1
## predictor: 1
## id: 1
##
## ── Operations
## • Text Normalization for: text
## • Variable mutation for: text, map_int(text, count_profane), ...
## • Text feature extraction for: text_copy
## • Tokenization for: text
## • Stop word removal for: text
## • Word embeddings aggregated from: textJetzt preppen:
rec2_prepped <- prep(rec2)Vielleicht macht es Sinn, sich das Objekt zur späteren Verwendung abzuspeichern.2 Feather verarbeitet nur Dataframes, daher nutzen wir hier RDS.
#write_rds(rec2_prepped, file = "~/datasets/Twitter/klassifik-rec2-prepped.rds")rec2_prepped <- read_rds("/Users/sebastiansaueruser/github-repos/hate-speech-data/objects/rec2_prepped.rds")Das Element rec2_prepped ist recht groß:
format(object.size(rec2_prepped), units = "Mb")
## [1] "113.8 Mb"Jetzt können wir das präparierte (“gepreppte”) Rezept “backen”:
rec2_baked <- bake(rec2_prepped, new_data = NULL)rec2_baked %>%
select(1:15) %>%
glimpse()
## Rows: 3,756
## Columns: 15
## $ id <fct> 5, 9, 10, 17, 27, 33, 42, 44, 48, …
## $ c1 <fct> OFFENSE, OFFENSE, OFFENSE, OFFENSE…
## $ profane_n <int> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ emo_words_n <int> 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1…
## $ emojis_n <int> 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0…
## $ wild_emojis_n <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ textfeature_text_copy_n_words <int> 16, 12, 15, 19, 15, 33, 30, 31, 6,…
## $ textfeature_text_copy_n_uq_words <int> 16, 12, 15, 17, 15, 32, 29, 29, 6,…
## $ textfeature_text_copy_n_charS <int> 121, 66, 119, 112, 101, 196, 171, …
## $ textfeature_text_copy_n_uq_charS <int> 31, 29, 30, 36, 31, 35, 42, 35, 23…
## $ textfeature_text_copy_n_digits <int> 0, 0, 0, 4, 0, 0, 0, 1, 0, 4, 2, 0…
## $ textfeature_text_copy_n_hashtags <int> 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ textfeature_text_copy_n_uq_hashtags <int> 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ textfeature_text_copy_n_mentions <int> 1, 1, 0, 0, 1, 1, 5, 1, 0, 1, 1, 1…
## $ textfeature_text_copy_n_uq_mentions <int> 1, 1, 0, 0, 1, 1, 5, 1, 0, 1, 1, 1…Das Rezept beinhaltet also einige Textfeatures plus die FastText-Worteinbettungen.
10.9.4 Fitting 3
wf3 <-
workflow() %>%
add_recipe(rec2) %>%
add_model(lasso_spec)
wf3
## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: logistic_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 6 Recipe Steps
##
## • step_text_normalization()
## • step_mutate()
## • step_textfeature()
## • step_tokenize()
## • step_stopwords()
## • step_word_embeddings()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Logistic Regression Model Specification (classification)
##
## Main Arguments:
## penalty = tune()
## mixture = 1
##
## Computational engine: glmnetTunen und Fitten:
#write_rds(fit3, "objects/chap-klassifik/chap_classific_fit3.rds")Hier ist die Performanz:
collect_metrics(fit3)autoplot(fit3)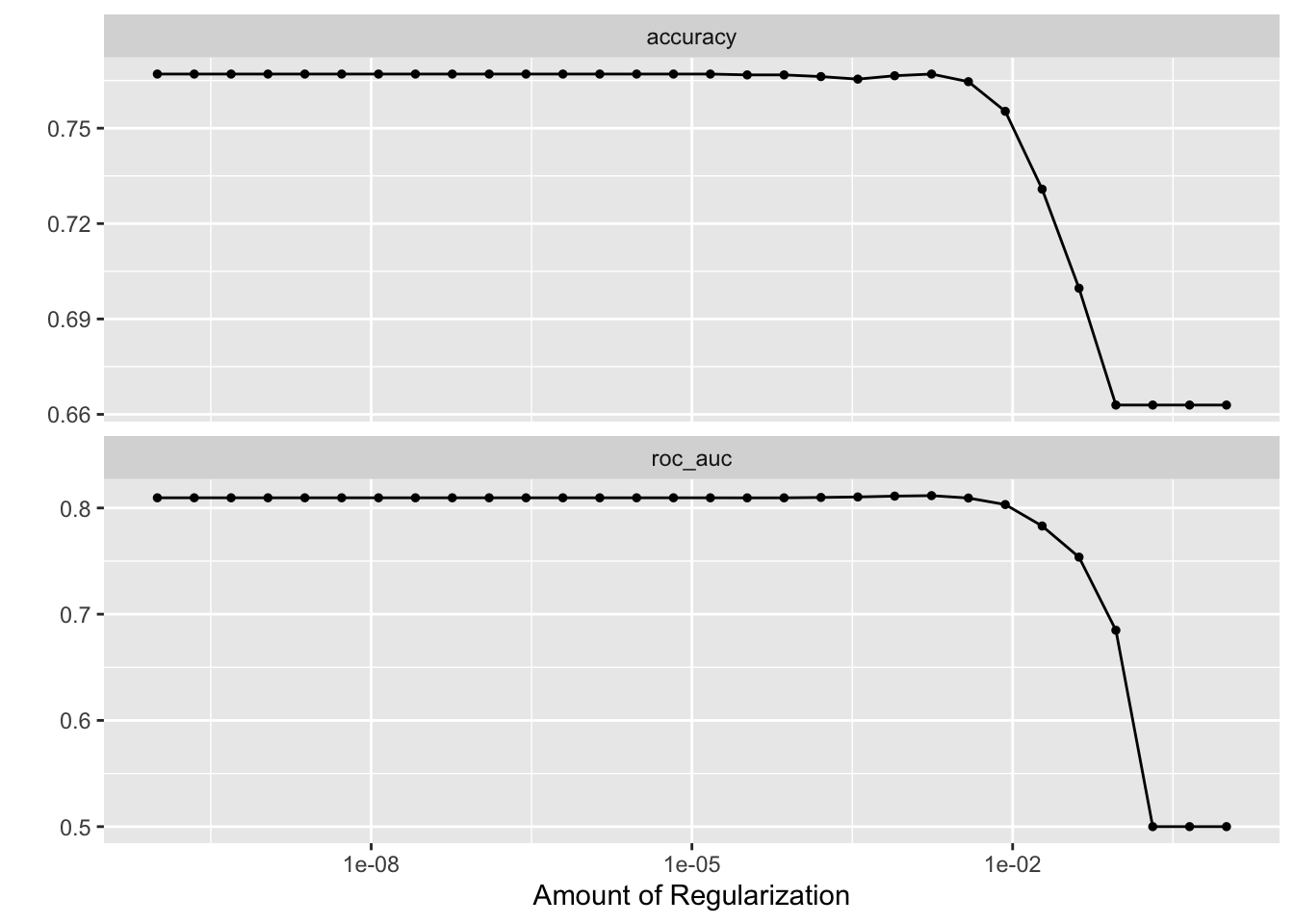
fit3 %>%
show_best("roc_auc")chosen_auc_fit3 <-
fit3 %>%
select_by_one_std_err(metric = "roc_auc", -penalty)Finalisieren:
wf3_final <-
finalize_workflow(wf3, chosen_auc_fit3)
wf3_final
## ══ Workflow ════════════════════════════════════════════════════════════════════
## Preprocessor: Recipe
## Model: logistic_reg()
##
## ── Preprocessor ────────────────────────────────────────────────────────────────
## 6 Recipe Steps
##
## • step_text_normalization()
## • step_mutate()
## • step_textfeature()
## • step_tokenize()
## • step_stopwords()
## • step_word_embeddings()
##
## ── Model ───────────────────────────────────────────────────────────────────────
## Logistic Regression Model Specification (classification)
##
## Main Arguments:
## penalty = 0.00853167852417281
## mixture = 1
##
## Computational engine: glmnet#fit3_final_train <- # die Berechnung kann dauern ...
fit(wf3_final, d_train)fit3_final_test <-
last_fit(wf3_final, d_split) # dauert etwasUnd endlich: Wie gut ist die Performanz?
collect_metrics(fit3_final_test)Am Ende so eines Arbeitsganges, bei dem man wieder (und wieder) die gleichen Funktionen kopiert, und nur aufpassen muss, aus fit2 an der richtigen Stelle fit3 zu machen: Da blickt man jedem Umbau dieses Codes zu einer Funktion freudig ins Gesicht.
Ein anderes Problem, für das hier keine elegante Lösung präsentiert wird, sind die langen Berechnungszeiten, die, wenn man Pech hat, auch noch mehrfach wiederholt werden müssen.
Die Gefahr mit dem Abspeichern via write_rds ist klar: Man riskiert, später ein veraltetes Objekt zu laden.
Zu diesen Punkten später mehr.
10.10 Fallstudien
Julia Silge stellt eine schöne Fallstudie zur Klassifikation von Spam-Mails bereit. In der Fallstudie geht es nicht um Feature Engineering, sondern um Modellierung.
ChatGPT generierten Text automatisch erkennen – wie gut geht das? Die Maschine erkennt sich selbst, im besten (oder schlechtesten?) Fall. Die Fallstudie zeigt, naja, so mittel, zumindest in den Daten in der Fallstudie.
OpenAIs Word-Einbettungen werden in dieser Fallstudie verwendet. Sehr schön!